TeamB-Fr
|
ou bien comment une souris peut-elle digérer un lion ? La problématique est réelle et de plus en plus fréquente : Nous devons souvent analyser des fichiers de grande taille, pour des taches comme la compression, cryptage, recherche etc Aujourdhui, des fichiers qui dépassent le giga ne sont pas rare, il suffit de se balader sur les réseaux de Peer to Peer pour sen convaincre ! Le problème est que charger en mémoire des fichiers de plusieurs dizaines de Mo suffit à paniquer le noyau qui gère la RAM...qui en récompense vous inflige un swap cyclonique à lorigine de vos pulsions du doigt sur le bouton Reset . Alors si vous voulez épater la galerie en expliquant que vous savez traiter des fichiers de plusieurs gigaoctets avec seulement quelques ko de buffer, lisez ce qui suit
Bases Pour récupérer le flux binaire stocké dans un fichier, le principe est simple : Nous ouvrons ce fichier. Ainsi fonctionne les logiciels comme Word, Excel, Photoshop etc. Ouvrir le fichier « sous entend » ici le transfert de toutes les données du fichier vers un espace mémoire précédemment alloué. Peut-être avez-vous remarqué, mais lorsque vous ouvrez un gros fichier Word, disons 20 Mo, la RAM disponible ne baisse pourtant pas de 20 Mo La technique consiste à découper le fichier en morceaux et à les charger au besoin (On retrouve dans la VCL des techniques similaires avec les buffers de données et les grilles de visualisation - DBGrid -). Au sens Windows du terme, ouvrir un fichier correspond plutôt à créer un handle (un identifiant windows) sur le fichier en question, puis ensuite toutes les manipulations de lecture, déplacement, écriture seffectuent à laide dappels aux API spécialisées par lintermédiaire de ce handle. Nous nappelons cependant pas directement ces API car nous avons à notre disposition des classes dédiées comme TFileStream. TFileStream est une classe qui sait obtenir un handle à partir dun nom de fichier, et qui est capable de lire et écrire dans ce fichier à laide des méthodes héritées de TStream : Read et Write. Voici un diagramme de classe situant TFileStream :
TFileStream offre les interface de création du fichier (création au sens général, c'est à dire création d'un handle sur un fichier désigné par son chemin). THandleStream obtient un handle sur un fichier et manipule ce dernier à partir du handle (les API requierent ce fameux handle) : Lecture, Deplacement et Ecriture. TStream comporte les attributs et méthodes de base à tous les gestionnaires de flux (size, position etc.).
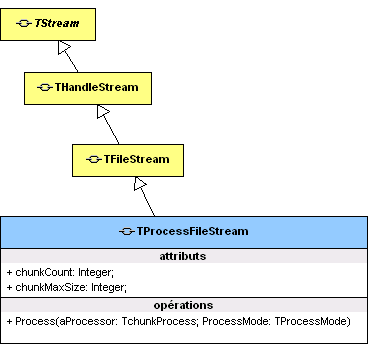
Nouvelle Classe : TProcessFileStream Nous allons exploiter l'existant et écrire une nouvelle classe, qui héritera de TFileStream, et qui sera capable de mettre en mémoire un fichier, morceau par morceau (chunk by chunk ou quignon de pain par quignon de pain comme vous préférez :-)), et une fois que ce morceau sera en mémoire, notre objet le mettra à disposition du développeur (sous forme de callback, mais on aurait aussi pu choisir une approche évènementielle). Effectuons un inventaire des futures capacités de notre objet, avec la liste - restreinte - de ses nouvelles propriétés et méthodes :
Diagramme avec la nouvelle TProcessFileStream *:
(* UML permet de n'afficher que ce que l'on désire, raison pour laquelle on ne découvre ici que les éléments les plus importants)
Fonctionnement interne de TProcessFileStream : Nous venons de modéliser notre future classe. Il faut bien comprendre comment la méthode Process est sensée fonctionner, ensuite nous nous attaquerons à l'implémentation. Lorsque nous appellons la méthode Process, nous lui passons deux paramètres :
C'est aProcessor qui demande de l'attention car il s'agit d'un paramètre au type un peu particulier : il est de type procédure d'objet. En effet étudions la définition de TChunkProcess : TChunkProcess = procedure(buffer: pointer; Size: integer) of object; Cette procédure d'objet attend deux paramètres : un pointeur sur un buffer et Size, un entier et c'est une procédure de ce type qui est passée en paramètre à la méthode TProcessFileStream.Process. Reprenons au début, admettons que nous appelons la méthode Process. Process s'exécute et pour chaque morceau de fichier (en fonction de chunkMaxSize et de ProcessMode) appelle la méthode aProcessor passée en paramètre à l'appel de Process. Ainsi pour chaque morceau du fichier cette méthode sera appelée, accompagnée des deux informations magiques : un pointeur sur la zone mémoire où est mis en buffer le morceau qui vient d'être lu, suivi de la taille de cette zone mémoire (ou du morceau c'est pareil). En définitive, la classe TProcessFileStream ne sait pas comment vont être exploités les morceaux du fichier qu'elle expose, elle se contente de fournir successivement les morceaux dans un buffer à la méthode passée en paramètre. On ne connait que le nom de cette méthode, mais pas forcément ce qu'elle fait. L'intérêt est de pouvoir profiter du mécanisme, en passant en paramètre à Process, n'importe quelle méthode pourvue qu'elle soit du type TChunkProcess. Ensuite ce que cette méthode fait avec le buffer, cela importe peu, le boulot de TProcessFileStream, qui consistait à exporter des morceaux d'un fichier vers une méthode externe, est terminé. Vous lirez plus loin un petit exemple qui vous aidera à assimiler et concrétiser ces petits concepts basés sur les callback.
implémentation Enfin un peu de code... Je sais que beaucoup de développeurs ont déjà les mains plongées dans le code avant de réfléchir aux fonctionnalités réelles de son projet, mais notre petite réflexion préalable était justifiée, si si :-)
EXPLOITATION Nous allons essayer notre classe à travers un petit exemple.
Exemple : Recherche des positions à laquelle on rencontre un octet spécifié. Une méthode de recherche d'une suite binaire complète est surement plus intéressante, mais il est plus prudent que l'on se concentre sur la manipulation de TProcessFileStream.
Créons un nouvel objet qui va nous servir de moteur de recherche d'un octet :
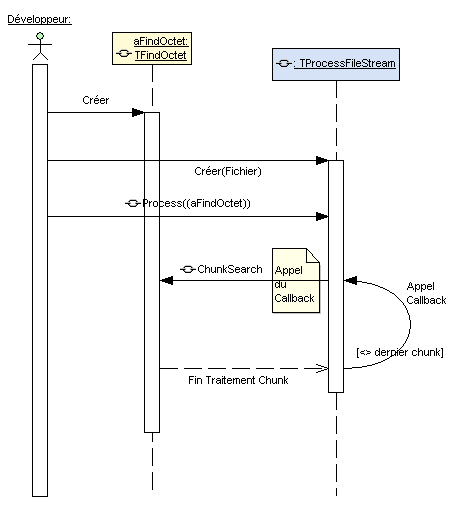
Dans un projet, faisons interagir nos deux objets selon le diagramme de séquence suivant (puisque dans D7 nous avons ModelMaker, l'excellent environnement UML, il serait dommage de ne pas s'amuser un peu... :-)
1. Nous créons un objet de type TFindOctet que nous nommerons aFindOctet et nous initialisons le byte à rechercher
aFindOctet := TFindOctet.Create; aFindOctet.ByteToFind := $D8; // $D8 est une valeur prise au hazard
2. Nous créons un objet TProcessFileStream, en indiquant un fichier existant en paramètre puis nous initialisons la taille des morceaux (chunk) de traitement.
aProcessFileStream := TProcessFileStream.Create(aFile, fmOpenReadWrite,
fmShareDenyWrite);
3. Nous appelons Process en passant en paramètre le callback vers l'objet aFindOctet
aProcessFileStream.Process(aFindOctet.ChunkSearch, pmByChunk);
4. Dès à présent, pour chaque morceau traité, la méthode ChunkSearch va être appelée (rappel du callback) avec en paramètres un buffer contenant le nouveau morceau du fichier à traiter, ainsi que la taille de ce morceau (qui peut différer si c'est le dernier morceau). La méthode callback ChunkSearch n'a plus qu'à faire son travail.
Conclusion A été présenté ici une méthode pour traiter des fichiers volumineux par lots. Nul doute que d'autres méthodes existent, d'ailleurs comme je le précisais plus haut, au lieu d'appeler un callback, j'aurais pu appeler un gestionnaire d'évènement. Ce sont des choix discutables, un peu hors sujet ici. Mais nous pouvons citer les MemoryMappedFiles, à manipuler via les API windows ou bien ce qui fera plaisir aux nostaliques du TurboPascal : BlockRead et BlockWrite. A vous de choisir une ou l'autre de ces techniques si celle décrite ici vous rend morose :-) Avec le principe du Callback, on peut concevoir que n'importe quelle méthode est donc susceptible de traiter ces paquets successifs de données, pourvu qu'elle interface le type TChunkProcess défini dans notre analyse. Les schémas UML de cet article n'étaient pas indispensables, mais ils étaient intéressants sur le plan documentaire visuel, en vous incitant aussi à utiliser le maximum des possibilités offertes par Delphi 7 Studio. Les développeurs ne possédant pas cette version pourront cependant compiler le code ci-dessus, et pour la partie UML, profiter des schémas de ce papier pour mieux comprendre. Comme d'habitude, si vous avez des questions, vous savez que la rédaction de Developpez.com est là pour vous soutenir au travers des tutoriaux, articles et forums.
TeamB-Fr Rédaction Developpez.com, Responsable Delphi
|